
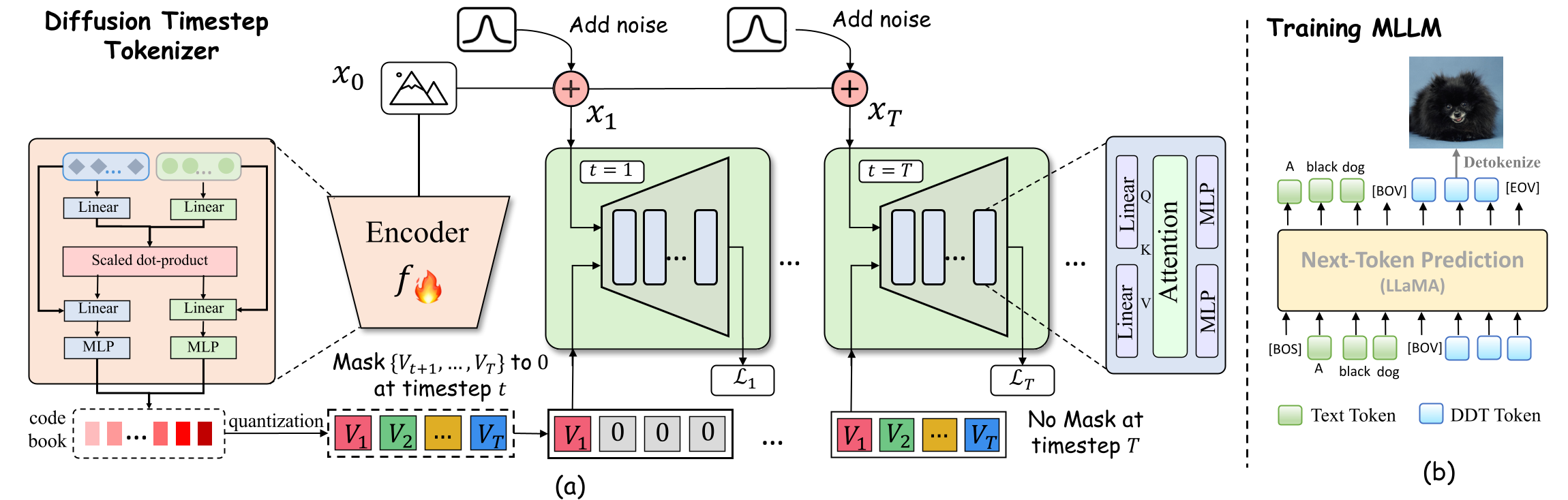
 DDT-LLaMA
DDT-LLaMA
Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens
News
【2025.03.30】 We are currently working on scaling up the training of our DDT tokenizer and the MLLM. In the near future (Maybe at the end of April ), we will release a more powerful version of DDT-LLaMA (We rename it as Selftok), along with a more detailed technical report. Stay tuned!
), we will release a more powerful version of DDT-LLaMA (We rename it as Selftok), along with a more detailed technical report. Stay tuned!
【2025.04.04】DDT-LLaMA has been accepted as an Oral Presentation at CVPR 2025!
【2025.04.25】 We are delighted to announce that the extended version of DDT-LLaMA, which we have renamed as Selftok, has been released! DDT-LLaMA presents the preliminary core ideas of Selftok, and Selftok, based on DDT-LLaMA, offers a more theoretical analysis and presents more comprehensive and improved results. You can find more details about Selftok at the following link.
【2025.05.15】 DDT-LLaMA is has been selected as an Award Candidate for Best Paper in CVPR 2025 (14/13008, top 0.1%). The code and model weights of DDT-LLaMA (Selftok) will be open-sourced at this link.
【2025.06.15】 DDT-LLaMA is awarded as CVPR2025 Best Student Paper Honorable Mention 🎉🎉🎉!
Introduction
Recent endeavors in Multimodal Large Language Models (MLLMs) aim to unify visual comprehension and generation by combining LLM and diffusion models, the state-of-the-art in each task, respectively. Existing approaches rely on spatial visual tokens, where image patches are encoded and arranged according to a spatial order (e.g., raster scan). However, we show that spatial tokens lack the recursive structure inherent to languages, hence form an impossible language for LLM to master. In this paper, we build a proper visual language by leveraging diffusion timesteps to learn discrete, recursive visual tokens. Our proposed ![]() DDT tokens recursively compensate for the progressive attribute loss in noisy images as timesteps increase, enabling the diffusion model to reconstruct the original image at any timestep. This approach allows us to develop
DDT tokens recursively compensate for the progressive attribute loss in noisy images as timesteps increase, enabling the diffusion model to reconstruct the original image at any timestep. This approach allows us to develop ![]() DDT-LLaMA, effectively integrating the strengths of LLMs in autoregressive reasoning and diffusion models in precise image generation, achieving seamless multimodal comprehension and generation within a unified framework.
DDT-LLaMA, effectively integrating the strengths of LLMs in autoregressive reasoning and diffusion models in precise image generation, achieving seamless multimodal comprehension and generation within a unified framework.
framework
![]() DDT tokens are RECURISIVE, which is reflected in token intrinsic semantics during tokenizer learning. Unlike spatial tokenizers decoding all tokens at once, each DDT token is related to diffusion timesteps, building on the semantics of preceding tokens to compensate for newly-lost info in the current timestep. From early to late timesteps, an expanding subset of DDT tokens is input to the decoder, with new tokens compensating for newly-lost semantics in each timestep. During diffusion process, fine-grained attributes such as texture are lost with less noise added (i.e., early time-steps), while coarse-grained ones such as shape are lost by adding more noise (i.e., late time-steps). So DDT tokens recursively acquire attributes ranging from fine-to-coarse and are semantically combined to construct the image.
DDT tokens are RECURISIVE, which is reflected in token intrinsic semantics during tokenizer learning. Unlike spatial tokenizers decoding all tokens at once, each DDT token is related to diffusion timesteps, building on the semantics of preceding tokens to compensate for newly-lost info in the current timestep. From early to late timesteps, an expanding subset of DDT tokens is input to the decoder, with new tokens compensating for newly-lost semantics in each timestep. During diffusion process, fine-grained attributes such as texture are lost with less noise added (i.e., early time-steps), while coarse-grained ones such as shape are lost by adding more noise (i.e., late time-steps). So DDT tokens recursively acquire attributes ranging from fine-to-coarse and are semantically combined to construct the image.
Based on such recursive visual tokens, we develop ![]() DDT-LLaMA through autoregressive multimodal pretraining. We find DDT-LLaMA effectively integrates the strengths of LLMs in autoregressive reasoning and diffusion models in precise image generation, achieving seamless multimodal comprehension and generation within a unified framework.
DDT-LLaMA through autoregressive multimodal pretraining. We find DDT-LLaMA effectively integrates the strengths of LLMs in autoregressive reasoning and diffusion models in precise image generation, achieving seamless multimodal comprehension and generation within a unified framework.
Q: Residual Tokenizers (such as VAR) design multiple tokens compensate for the information loss in a single quantization operation. What is the difference from Residual Tokenizers?
A: Residual tokenizer aims to approximate the visual feature more precisely in a single quantization operation, WITHOUT altering the essence of 'spatial tokenizer'. It divides tokens into multi-scales (from lower to higher resolutions) and the reconstructed image visually appears as the mixup of images from each scale.In contrast, DDT tokens are NOT spatial tokens, binding token decoding with diffusion timesteps. From early to late timesteps, an expanding subset of DDT tokens is input to the decoder, with new tokens compensating for newly-lost semantics in each timestep. So tokens recursively acquire attributes ranging from fine-to-coarse and are semantically combined to construct the image.
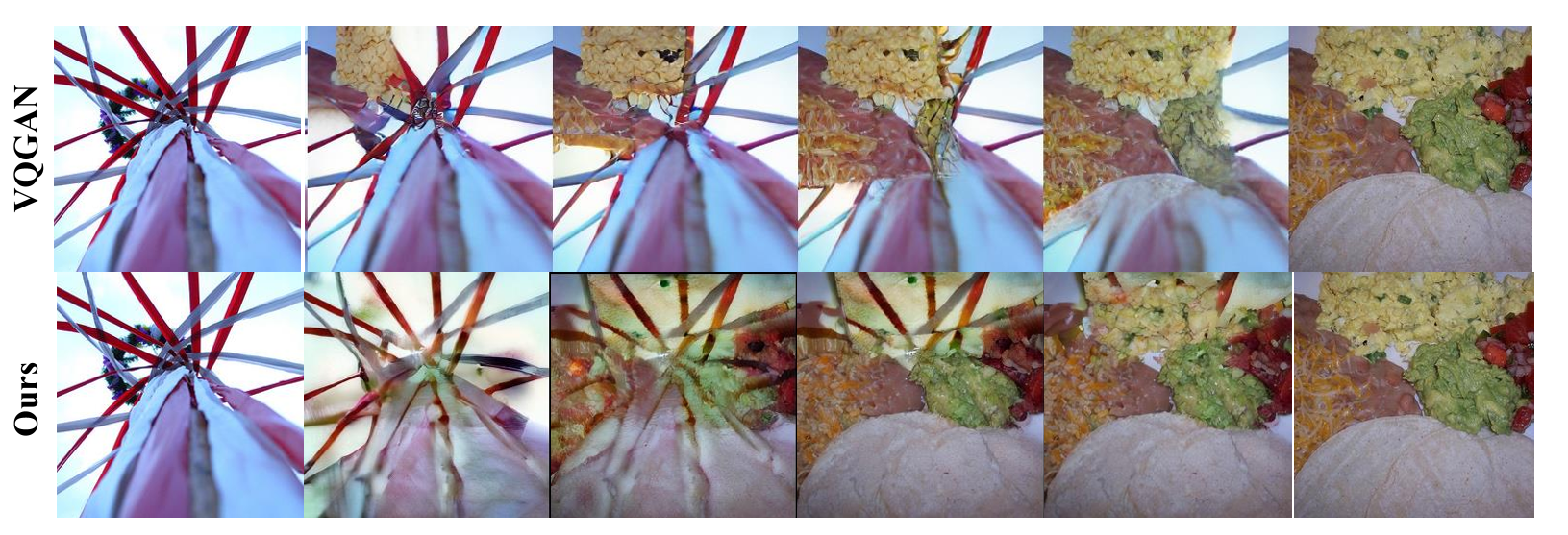
Below, we demonstrate examples of counterfactual interpolation using two images to further illustrate that VQGAN tokens and VAR tokens are spatial tokens (similar to cutmix or mixup), while DDT-tokens are semantic tokens.



ddt tokens are recursive
Progressively Image Decoding
To illustrate the recursive nature of DDT tokens, we only input a subset of the first t timestep tokens that are autoregressively sampled by DDT-LLaMA, into the decoder for image synthesis (t ranges from 1 to 480). As shown in the following figure, with the number of tokens increasing, the image's attributes are progressively recovered. Initially, the decoder reconstructs fine details, with coarse-grained information such as contours and color information gradually completed until the full structure of the image is outlined. It demonstrates that DDT tokens recursively disentangle visual attributes ranging from fine-to-coarse and are semantically combined to construct the image.

To more intuitively illustrate the differences in the token properties of spatial tokens (such as VQGAN tokens) and DDT tokens, we utilize a autoregressive class-conditional pretrained GPT model on DDT tokens to sample a series of images. We then encode the corresponding DDT tokens and VQGAN tokens for each image. For both types of tokens, we feed the corresponding tokenizer decoder with an expanding subset of tokens to decode the images, and present these images in the form of a GIF. It is evident that DDT tokens represent a combination of visual attributes of an image, while VQGAN tokens are a concatenation of different spatial regions of the image.
DDT tokens![]()

VQGAN tokens![]()

Counterfactual Interpolation
We further conduct counterfactual interpolation with both DDT tokens and VQGAN tokens. Specifically, for the token sequence derived from an image, we replace a subset of tokens with those from another image, while keeping the remaining tokens fixed, with the resulting sequence fed into the decoder for image generation. As shown in the following figure, for VQGAN tokens, counterfactual interpolation actually performs CutMix, where regions from two images are concatenated. In contrast, DDT tokens, with their disentangled representation, ensure that only the attributes captured by the substituted tokens change in the generated counterfactuals, which allows for a seamless semantic blending of the two images.




qualitative examples of ddt-llama
T2I Generation
DDT-LLaMA can effectively follows various types of instructions, including complex ones such as generating surreal images and multi-condition combined prompts, to generate semantically-consistent images. Of course, there is room for improvement in the aesthetic quality of the images. This limitation stems from the fact that our current tokenizer was only trained on ImageNet with a resolution of 256x256.


Here we present a direct comparison between DDT-LLaMA and Emu3 on prompts involving counting, color, and position. Though Emu3 generates images with higher aesthetic quality, it struggles to accurately respond to such prompts. In contrast, DDT-LLaMA generates images that better align with the object attributes and the spatial relationships specified in the prompt.






Image Editing
DDT-LLaMA supports a wide spectrum of editing operations including both local change (e.g., removal, replacement) and global change (change time, manipulation). For each case, the output images not only resemble the source image to a high degree but also are coherent with the instruction, demonstrating that DDT-LLaMA achieves a great trade-off between fidelity and editability.


Scaling Law on T2I
We have also observed preliminary indications of scaling laws in our DDT-based MLLM. we also leverage Gemma2-2b for pre-training. And we further compare performance of T2I generation with two model sizes (2B,8B) at three different training stages (50\%, 75\%, and 100\% of total training tokens), as shown in the following figure. The observed improvements in visual quality align with scaling laws, which suggest that larger transformers trained on more extensive datasets can learn more detailed and fine-grained image distributions.

BibTeX
@article{pan2025generative,
title={Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens},
author={Pan, Kaihang and Lin, Wang and Yue, Zhongqi and Ao, Tenglong and Jia, Liyu and Zhao, Wei and Li, Juncheng and Tang, Siliang and Zhang, Hanwang},
journal={arXiv preprint arXiv:2504.14666},
year={2025}
}